SGGpoint
Exploiting Edge-Oriented Reasoning for 3D Point-based Scene Graph Analysis (CVPR2021)
Dataset Description
For our real-world SGGpoint studies, we manually checked and carefully revised the raw 3DSSG datasets (extended from 3RScan) to a cleaned version (3DSSG-O27R16), with mappings to more popular and meaningful sets of instance semantics & structural relationships. 3DSSG-O27R16 stands for the preprocessed 3DSSG dataset annotated with 27 Object classes and 16 types of structural Relationships - please refer to our [Supp.] for more info.
To download our preprocessed 3DSSG-O27R16 dataset, please follow the instructions in our project page - or you could also derive these preprocessed data yourselves by following the step-by-step guidance below.
Structure of our 3DSSG-O27R16. There are mainly two kinds of files in our dataset, namely the dense 10-dim point cloud representitaons ("10dimPoints") and our updated scene graph annotations ("SceneGraphAnnotation.json"). Two preprocessing scripts (one for point_cloud_sampling and one for scene_graph_remapping) are available in this repository. The dict structure of SceneGraphAnnotation.json is summarized below:
SceneGraphAnnotation.json
Structure -> {
...,
scene_id: {
'nodes': {
...,
obj_id: {
'instance_id': obj_id,
'instance_color': instance_color_encoding,
'rio27_enc': rio27_class_id,
'rio27_name': rio27_class_name,
'raw528_enc': raw528_class_id,
'raw528_name': raw528_class_name,
},
...
},
'edges': [
...,
[src_obj_id, dst_obj_id, rel_class_id, rel_class_name],
...
]
},
...
}
Example -> {
...,
'f62fd5fd-9a3f-2f44-883a-1e5cf819608e': {
'nodes': {
...,
'11': {
'instance_id': 11,
'instance_color': '#c49c94',
'rio27_enc': 3,
'rio27_name': 'cabinet',
'raw528_enc': 68,
'raw528_name': 'cabinet',
},
'40': {
'instance_id': 40,
'instance_color': '#cd7864',
'rio27_enc': 12,
'rio27_name': 'curtain',
'raw528_enc': 129,
'raw528_name': 'curtain',
},
...
},
'edges': [
...,
['54', '8', '3', 'lying on'],
['35', '8', '15', 'close by'],
['20', '2', '14', 'spatial proximity'],
['15', '4', '1', 'attached to'],
...
]
},
...
}
Dataset Preprocessing
Below we would go through and explain each preprocessing step in generating our 3DSSG-O27R16 dataset (for your information and interests only):
A. Point Cloud Sampling
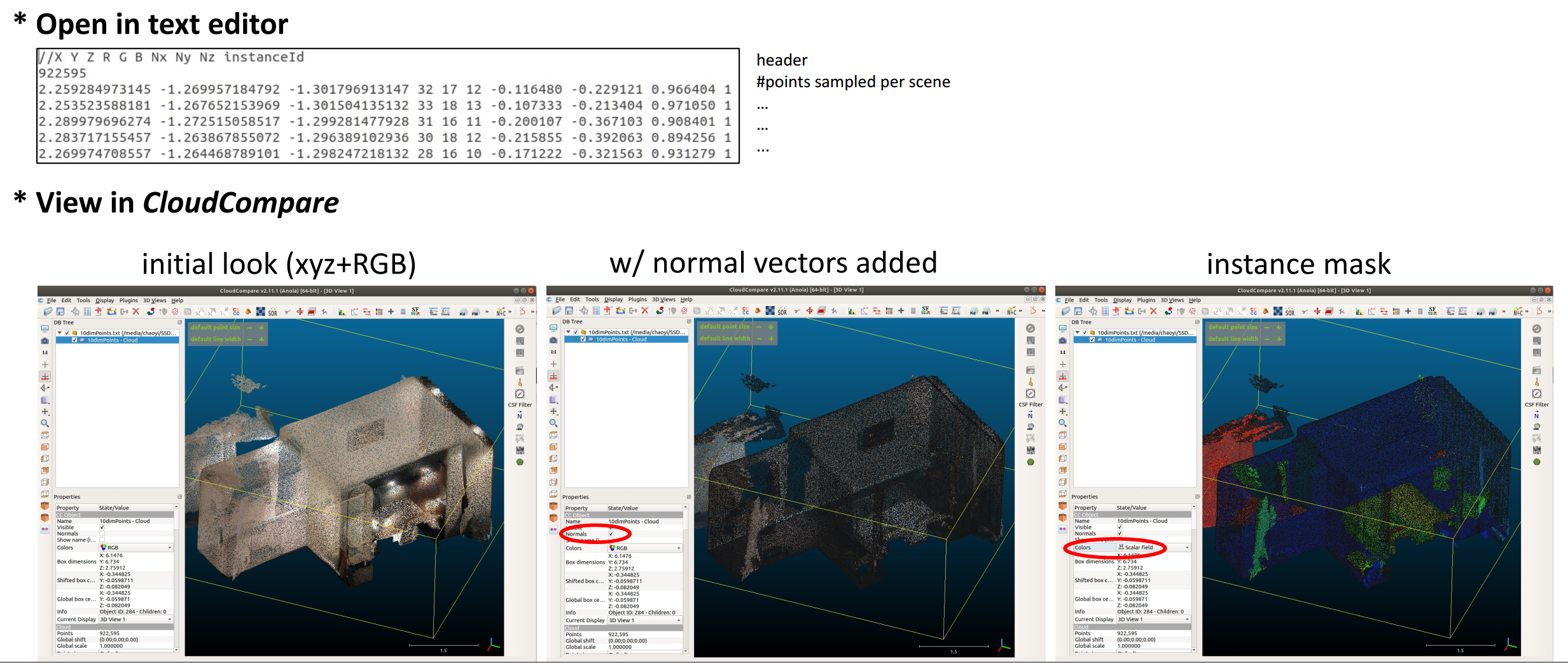
sampling 10-dim point cloud from obj files with mesh info. discarded.
- CloudCompare software is adopted for sampling dense point cloud representations (PC9-dim) for scenes encoded within the raw mesh.refined.obj files. The surface density was set to 10k points per square unit, and the generated point clouds are of 9-dim (3-dim coordinate, 3-dim color, and 3-dim normal vector). Our corresponding batch sampling script is available here.
- Fetch a relatively sparse point cloud instance mask (IM4-dim) (with per-point instance_idx annotation) from the raw labels.instances.annotated.ply files.
- Overlap IM4-dim to PC9-dim to generate the desired 10-dim dense point cloud representations, including the information of 3-dim coordinate (x, y, z), 3-dim color (R, G, B), 3-dim normal vector (Nx, Ny, Nz), and 1-dim instance_idx. Specifically, the instance annotation for each point from PC9-dim is decidied as the corresponding annotation of its nearest point from IM4-dim. These outputs are saved as "10dimPoints/[Scene_IDx].txt" in our 3DSSG-O27R16 dataset.
- Some quick demo.
B. Updates on Scene Graph Annotations
full lists of remapped & relabelled annotations can be found in our [Supp.].
- Node (object) Remapping: Remap raw object classes into their another popular 27-class set (RIO27). Note: there exist 28 unique ID-Label pairs under the [“RIO27 Mapping” coloum], including an unexpected
"0 : -"annotation - which contains a few rare objects such asjuicer,hand dryer,baby bed, andcosmetics kit. As the handling of data imbalance is out of our focused research scope, we would treat them as invalid objects under our task context in Recalibration Step below. - Edge (Relationship) Relabelling: The raw semi-automatically generated 3DSSG dataset is a mix beween semi-automatic computation and manual annotation. To improve edge-level annotation quality, we manually checked and corrected through the following sub-steps to derive a multi-class label set (rather than a multi-label set) of meaningful structure relationships:
- We firstly removed all comparative annotations (e.g.,
big1ger-than,same-material, andmore-comfortable-than) to focus more on the structural relationships (e.g.,standing-on,leaning-against), resulting in a 19-class label set. - We aggregated four directional proximity relationships (namely,
left,right,behind, andfront- which could be easily decided by the bbox centers in post-processing we suppose) into one NEW type named asSpatial Proximity. This aggregation addresses ill-posed orientation-variant observations on inter-object relationships (and therefore, releases the power of rotation-involved data augmentation techniques), resulting in a 16-class label set now.
* Recall from 3DSSG: these directional proximity relationships are only considered and annotated between the nodes that share a support parent => The same condition applies to our 'Spatial Proximity' now. - We then noticed the majority (nearly 80%) of edge annotation was under multi-class setting already, while the resting multi-label edges mainly conflicted to the ambiguous
close-byannotation. After a careful study, we managed to produce a multi-class label set through strategies below. TL;NR: we re-definedclose-by1 andSpatial Proximity2 relations, such that a priority list of interests can be retained as “?>Spatial Proximity>close-by”.
Let '?' denotes any other labels except for 'Spatial Proximity' and 'close-by', such as 'connected-to', 'standing-on', and 'attached-to'.All Cases (Ratio) Descriptions Solution w/ Explanation Normal (79.4%) [ Spatial Proximity] or [close-by] or [?]N/A. Within expected multi-class setting already, i.e., 1 label per edge. Case 1 (20.5%) [ close-by,Spatial Proximity] (20.4%) or [close-by,?] (0.1%)Relabel Case 1 by the removal of close-by. Ignoringclose-byas long as there exists a more meaningful and specific structural relationship.1Case 2 (0.001%) [ Spatial Proximity,?]Relabel Case 2 as ?. For these very rare cases where two objects share one support parent (Spatial Proximity) AND they also have another mearningful relation (?), we’d like to focus more on the higher-level one.2Case 3 (0.04%) [ Spatial Proximity,close-by,?]Relabel Case 3 as ?. Merging from Case 1 & 2 above.1In other words,
close-by(after relabelling) is now describing the relationship between two objects who are spatially close to each other AND they have no extra high-level structural relationships includingSpatial Proximity.
2Spatial Proximity(after relabelling) - two objects have a spatial relationship (amongleft,right,behind, andfront) with each other AND they share a support parent AND they have no higher-level relations (?) in between. - Now we derive a multi-class structural relationship set for edge predictions.
- We firstly removed all comparative annotations (e.g.,
- Recallibraition between node and edge annotations simultaneously. 1) Remove all edges connected to invalid nodes. 2) Iterate among edges, find the isolated nodes (with no edges connected to) for each scene, and remove them as well. 3) Apart from the small / paritial scenes (list), there is one more special scene to be removed (i.e., 87e6cf79-9d1a-289f-845c-abe4deb8642f) who contains no elements after our above cleanings (see more details in our scene_graph_remapping script). Our scene graph annotations derived after this step are saved as "SceneGraphAnnotation.json" in our 3DSSG-O27R16 dataset.
Last Few Steps
Within dataloader.py
- Filtering out the point cloud instances with no matches found in cleaned Scene Graph annotations above. Apart from being compatible to our changes above, this step would also fix a few inperfect annotating issues (e.g., some instances only appear in the scenes but missing in scene graph annotation) within the raw 3DSSG.
- Below is some pseudo-code for REMOVING invalid & mismatched nodes from pointclouds
for each scene in scene_data: # split pointcloud (9-dim) and instance_idx (1-dim) from the 10dimPoints file unique_instance_idx_in_pointcloud = set(np.unique(instance_idx)) # suppose unique_instance_idx_in_scenegraph denotes the unique ids per scene from SceneGraphAnnotation file diff = list(unique_instance_idx_in_pointcloud.difference(unique_instance_idx_in_scenegraph)) # ignore the mismatched instances num_invalid_node = np.sum(instance_idx <= 0) # ignore the invalid nodes if len(diff) > 0 or num_invalid_node > 0: valid_index = (instance_idx > 0) # ignore the invalid nodes for diff_value in diff: # ignore the mismatched instances curr_valid_index = (instance_idx != diff_value) valid_index *= curr_valid_index pointcloud = pointcloud[valid_index] instance_idx = instance_idx[valid_index] # print('after :', instance_idx.shape, pointcloud.shape, valid_index.shape) # uncomment if you'd like to check the point_num chanages # DESIRED OUTPUTS now: pointcloud & instance_idx - Below is some pseudo-code for CHECKING invalid & mismatched nodes in pointclouds
diff1 = unique_instance_idx_in_scenegraph.difference(unique_instance_idx_in_pointcloud) diff2 = unique_instance_idx_in_pointcloud.difference(unique_instance_idx_in_scenegraph) assert len(diff1) == len(diff2) == 0, "Something wrong: {}- \n{} - \n{}".format(scene_name, unique_instance_idx_in_pointcloud, unique_instance_idx_in_scenegraph)
- Below is some pseudo-code for REMOVING invalid & mismatched nodes from pointclouds
-
Data augmentation - random sampling constant number of (4096) points for each scene of larger size. To ensure a uniform sampling (that could be applied on each individual object), we compute a dynamic sampling_ratio for each scene of different size - and use it to achieve cropping_by_instance_idx() to guarantee that all objects could be fairly sampled each loading time (without the influences caused by object scale differences). See [Supp.] for more relevant details.
def cropping_by_instance_idx(self, instance_labels): # instance_labels is the 1-dim instance_idx above. if instance_labels.shape[0] > self.max_npoint: # self.max_npoint is set to 4096 sampling_ratio = self.max_npoint / instance_labels.shape[0] all_idxs = [] # scene-level instance_idx of points being selected this time for iid in np.unique(instance_labels): # sample points on object-level indices = (instance_labels == iid).nonzero()[0] # locate these points of a specific instance_idx end = int(sampling_ratio * len(indices)) + 1 # num_of_points_to_be_sampled + 1 np.random.shuffle(indices) # uniform sampling among each object instance selected_indices = indices[ :end] # get the LuckyPoints that get selected in fortune's favourite all_idxs.extend(selected_indices) # append them to the scene-level list valid_idxs = np.array(all_idxs) else: valid_idxs = np.ones(instance_labels.shape, dtype=bool) # no sampling is required return valid_idxs # somewhere in dataloader _valid_idxs_ = self.cropping_by_instance_idx(instance_labels) # 10dimPoints = xyz + rgb + normal + instance_idx (semantic_labels are fetched from searching instance_idx within SceneGraphAnnotation) xyz = xyz[_valid_idxs_] rgb = rgb[_valid_idxs_] normal = normal[_valid_idxs_] semantic_labels = semantic_labels[_valid_idxs_] instance_labels = instance_labels[_valid_idxs_] - Data augmentation - other operations on point cloud representations. Borrowed from PointGroup.
- Reordering instance_idx per batch. In our PyTorch (and torch_geometric) implementations, we achieved the batch training (on varying num_node graphs) by aggregating these individual scene graphs into one big but isolated graph.
- For example, given a batch_size B > 1, we have B scene graphs with varying number of nodes per each batch (say, their node_num as N1, N2, …, NB), we could simply aggregate them into 1 big graph containing B isolated sub-graphs.
- These isolated sub-graphs would not mess with others in the following node/edge propagations, which could be guaranteed by reordering their instance_idx to a
rangelist of length (N1 + N2 + … + NB). - This mapping (old instance_idx -> reordered instance_idx) is globally shared among each batch. Note: this instance_idx reordering operation also need to be applied on the edges.